
Next: Préconditionnement Up: Chap. 6 : Méthodes Previous: Programmation à l'aide du
Il s'agit maintenant d'estimer la mémoire et le nombre d'opérations
nécessaires à la résolution du système linéaire
![]() . Nous considérons les cas suivants :
. Nous considérons les cas suivants :
La décomposition de Cholesky de la matrice ![]() nécessite le stockage
de la bande, soit
nécessite le stockage
de la bande, soit
![]() coefficients. Le nombre d'opérations
nécessaire à la décomposition est d'ordre
coefficients. Le nombre d'opérations
nécessaire à la décomposition est d'ordre
![]() (théorème 5.4 du livre).
(théorème 5.4 du livre).
En ce qui concerne l'algorithme
du gradient conjugué, seuls les éléments non-nuls de la matrice
![]() doivent être stockés, soit moins de
doivent être stockés, soit moins de ![]() coefficients.
Les expériences numériques montrent que le nombre d'itérations
nécessaire à la convergence de l'algorithme
est d'ordre
coefficients.
Les expériences numériques montrent que le nombre d'itérations
nécessaire à la convergence de l'algorithme
est d'ordre ![]() . A chaque itération, le coût principal est celui
d'une multiplication matrice-vecteur, soit moins de
. A chaque itération, le coût principal est celui
d'une multiplication matrice-vecteur, soit moins de ![]() opérations.
Par conséquent, le nombre d'opérations de l'algorithme
du gradient conjugué est de l'ordre de
opérations.
Par conséquent, le nombre d'opérations de l'algorithme
du gradient conjugué est de l'ordre de ![]() .
.
Les résultats sont résumés dans le tableau ci-dessous.
| méthode | mémoire | opérations |
| directe | ||
| itérative |
A l'aide des fonctions flops et whos de Matlab, nous
avons comparé le nombre d'opérations ainsi que la mémoire
nécessaire à la mise en oeuvre des deux algorithmes
pour différentes valeurs de ![]() (pour la mise en oeuvre de la
décomposition de Cholesky avec Matlab,
voir le chapitre 5 du support de cours).
(pour la mise en oeuvre de la
décomposition de Cholesky avec Matlab,
voir le chapitre 5 du support de cours).
Le nombre d'opérations (en millions) est reporté dans le tableau suivant :
| méthode directe | méthode itérative | |
| 20 | 0.197 | 0.694 |
| 40 | 2.86 | 5.48 |
| 80 | 43.3 | 42.8 |
| 160 | 674 | 331 |
Nous observons donc que
En ce qui concerne la place mémoire, rappelons que pour ![]() les coefficients non-nuls des matrices
les coefficients non-nuls des matrices ![]() et
et ![]() (avec
(avec ![]() )
sont
)
sont
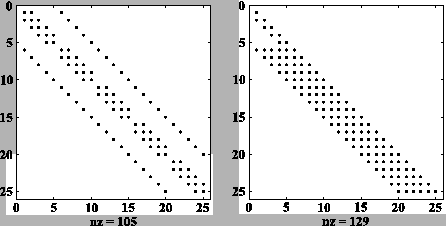
La place mémoire nécessaire au stockage de ![]() et
et ![]() (en millions de ``double'') est reporté dans le tableau suivant :
(en millions de ``double'') est reporté dans le tableau suivant :
| mémoire pour |
mémoire pour |
|
| 20 | 0.0294 | 0.0978 |
| 40 | 0.119 | 0.775 |
| 80 | 0.482 | 6.17 |
| 160 | 1.94 | 49.2 |
Nous observons donc que
Nous concluons donc en affirmant que, lorsque ![]() est grand,
l'algorithme du gradient conjugué
est plus performant que la décomposition de Cholesky
pour la résolution du système linéaire
est grand,
l'algorithme du gradient conjugué
est plus performant que la décomposition de Cholesky
pour la résolution du système linéaire
![]() , la matrice
, la matrice ![]() étant définie par la figure ci-dessous.
étant définie par la figure ci-dessous.
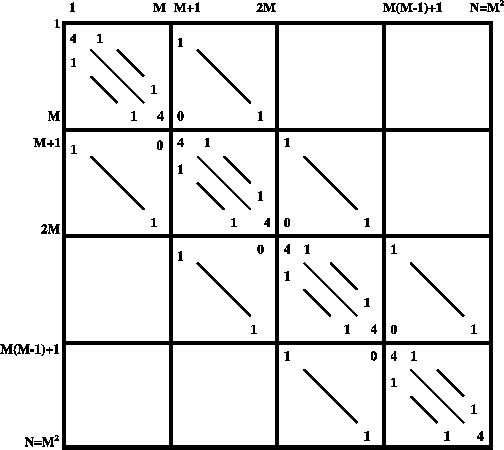
Ces résultats sont généralisables au cas où la matrice
![]() est celle obtenue lorsqu'on utilise une méthode d'éléments
finis continus de degré un (voir la section 11.2 du livre).
est celle obtenue lorsqu'on utilise une méthode d'éléments
finis continus de degré un (voir la section 11.2 du livre).
EPFL-IACS-ASN